



voriges Kapitel | nächstes Kapitel
4.3 Effekte der Einzelspuren
Die in den vorigen Kapiteln aufgezeichneten Audiosignale mußten den heutzutage üblichen Gewohnheiten von Musikhörern angepasst werden. In ihrer rohen, d.h. effektfreien Form erscheinen Tonaufnahmen den meisten Menschen als „nicht hochwertig“, „schlecht klingend“ oder „zu dünn“. Die Palette der Kritikpunkte an rohen Audioaufnahmen ist dabei unübersichtlich groß. Hinzu kommt, dass verschiedene Audiospuren in ihrer Ursprungsform in denselben Frequenzbereichen hohe Lautstärkeanteile haben, was zu einem verwaschenen und auch in der Regel schlecht bewerteten Sound führen kann, wenn diese zusammen abgespielt werden. Wie Abbildung 29 zeigt, besteht der Beispielsong sogar aus 21 verschiedenen Spuren, die aber gemeinsam gut klingen sollen. In diesem Kapitel sollen verschiedene Audioeffekte beschrieben werden, die dazu dienen, Mängel der beschriebenen Art zu beseitigen. Diese Effekte manipulieren zum einen die Gesamtdynamik, sowie die Dynamik einzelner Frequenzen, oder fügen Klangcharakteristika auf Grundlage des Basismaterials hinzu. Zusätzlich wird beschrieben in welchem Umfang diese Effekte an welchen Spuren angewandt wurden.
4.3.1 Dynamiken
Ein wichtiger Bereich der postmanipulativen Effekte sind jene, die auf Grundlage der Lautstärke des Eingangssignal (in der Regel die rohe Audiospur) Einfluß auf die Lautstärke des Ausgangssignals nehmen. In Hostprogrammen wie Cubase sind diese Effekte, die ebenfalls über die VST Schnittstelle angesprochen werden, als „Dynamics“ bezeichnet und enthalten für gewöhnlich Gate, Kompressor und Limiter.
Ein Gate betrachtet zur Echtzeit die jeweils aktuelle Lautstärke des Eingangssignals. Fällt diese Lautstärke unter eine gewisse, durch den Tontechniker vorgegebene Schwelle (englisch: Threshold) angegeben in Dezibel, dann wird das Ausgangssignal auf stumm geschaltet. Abbildung 30 zeigt die Funktionsweise eines Gates:
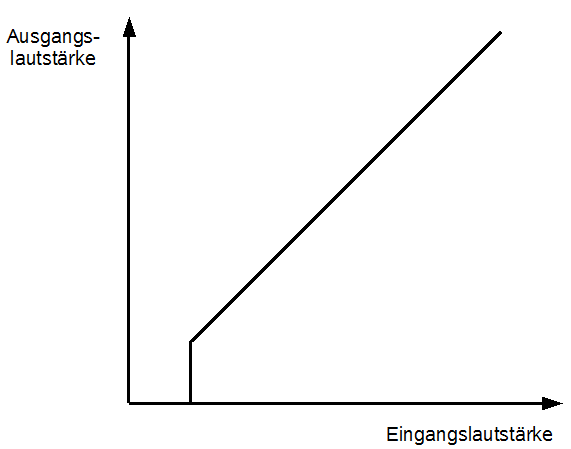
Abbildung 30: Gate
Zusätzlich zum Threshold, der in der Abbildung die Position des vertikalen Verlaufes bezüglich der X-Achse bestimmt, enthält ein Gate in aller Regel noch Attack- und Release-Regler. Diese bestimmen die Zeit in Millisekunden, nach denen das Gate schließt (Attack), bzw. wieder öffnet (Release). Ein Gate kann dazu gebraucht werden, um aufnahmebedingtes Rauschen zu unterdrücken. Das eigentliche Nutzsignal, das weitaus lauter als das Rauschen ist, kann das Gate passieren, das Rauschen selbst wird jedoch herausgefiltert, sofern es unterhalb der Schwelle liegt. Um unangenehme und abgehackt klingende Effekte bei relativ betrachtet leisen und kurzen Passagen des Nutzsignals zu vermeiden, kann die Attack-Zeit etwas größer gewählt werden. dasselbe gilt umgekehrt für die Release-Zeit: soll zum Beispiel ein Knacksen, wie auf alten LP Aufnahmen üblich, gefiltert werden, dann könnte man die Release Zeit geringfügig höher einstellen, als die Zeit, die ein Knacksen in Anspruch nimmt, damit es das Gate nicht öffnet.
Im Beispielsong wurde vor allem die Sologitarre mit einem Gate gefiltert, da die Tonabnehmer einer E-Gitarre prinzipbedingt ein Rauschen erzeugen. Durch das Gate wurde dies nachträglich wieder entfernt.
Ein Kompressor ist, bezogen auf die Hörgewohnheiten im 21. Jahrhundert, der wohl wichtigste Effekt, um im Ohr des naiven Zuhörers einen professionellen Klang zu erzeugen. Tatsächlich wird ein Kompressor höchst ausgiebig in moderner Popmusik angewandt. Abbildung 31 zeigt die Arbeitsweise eines Kompressors:
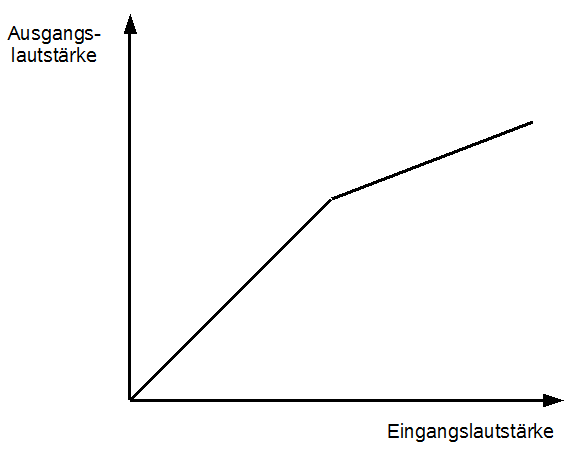
Abbildung 31: Kompressor
Wie bereits beim Gate entscheidet auch beim Kompressor ein vom Tontechniker eingestellter Threshold über Aktivierung und Deaktivierung des Effekts. Ebenso entscheiden Attack- und Releasezeiten über die Zeiträume, nach denen bei Eintritt der Bedingung (= Überschreitung oder Unterschreitung des Thresholds) der Effekt angewandt (bzw. deaktiviert) wird. Wie in der Abbildung zu sehen ist, „knickt“ die Gleichheit von Eingangslautstärke und Ausgangslautstärke an einem gewissen Punkt (dem Threshold) ab. Anders ausgedrückt: das Ausgangssignal wird ab einer bestimmten Lautstärke weniger schnell laut, als das Eingangssignal. Das Verhältnis, in dem dies geschieht, wird über einen zusätzlichen Regler an einem Kompressor eingestellt, dem sogenannten „Ratio“. Übliche Werte sind hier 1:1, 1:2, 1:4, 1:8 und 1:∞, wobei dies je nach Kompressor auch stufenlos regelbar sein kann. 1:1 entspricht dabei keinem Kompressor (in der Abbildung also einer durchgezogenen Winkelhalbierenden) und 1:∞ verhindert konsequent, dass das Ausgangssignal über eine bestimmten Pegel gehen kann. In diesem Falle spricht man auch von einem Limiter. Siehe Abbildung 32.
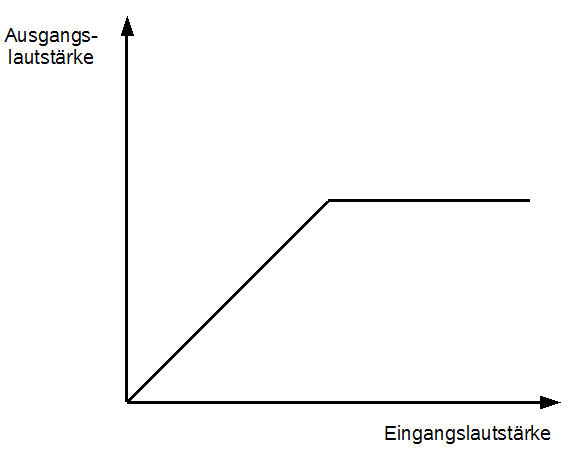
Abbildung 32: Limiter
Der Limiter ist also ein Kompressor mit einer Ratio von 1 zu Unendlich. Praxisnah ausgedrückt regelt ein Kompressor laute Passagen herunter, ohne dabei bereits leise Passagen in ihrer Lautstärke zu reduzieren. Ein letzter, zusätzlicher Regler, oftmals beschriftet mit „Gain“ oder „Output Gain“, hebt die Gesamtlautstärke des Ausgangssignal wieder an, um die Lautheitsverluste bei der Kompression zu kompensieren. Eine Art Faustregel ist also, dass ein Kompressor laute Stellen leise und leise Stellen laut macht.
Besonders der Gesang profitiert von der Anwendung eines Kompressors, da die menschliche Stimme naturgemäß stark in ihrer Lautstärke variiert. Dies ist nicht nur der Fall, weil es in einem Lied leise und laut gesungene Passagen geben kann, sondern auch weil der Abstand des Sängers zu seinem Mikrofon selbst im Studio keine Konstante sein kann. Es gibt in moderner Musik kaum Tonquellen, die nicht komprimiert werden. Höchstens experimentelle Jazzaufnahmen verzichten bewußt auf die Anwendung eines Kompressors.
Alte Aufnahmen von Bands wie den Beatles, Rolling Stones oder Deep Purple verwenden noch keinen oder kaum Kompressor, wodurch der Gesang für heutige Hörgewohnheiten ungewohnt bis penetrant klingen kann. Ein Kompressor gleicht die Lautstärkeverhältnisse innerhalb eines Signals an und macht vor allem hochdynamische Instrumente, zu denen man vor allem die Stimme und Blasinstrumente zählen kann, angenehmer hörbar.
Im Beispielsong kam ein Kompressor vor allem bei den Gesangsspuren zur Anwendung, um unterschiedlich laute Passagen, auch bedingt durch unterschiedliche Tonhöhen (hohe Töne müssen gewöhnlich lauter gesungen werden), einander anzugleichen. Verzerrte Gitarren, wie Sologitarre oder Rhythmusgitarre, überschreiten ein gewisses Lautstärkemaß nicht und erscheinen in Bezug auf ihrer Dynamik sehr homogen. Daher ist die Anwendung eines Kompressors hier in der Regel nicht nötig. Das Schlagzeug benutzt ebenfalls einen Kompressor, der in dem oben beschriebenen externen Klangerzeuger zu finden ist. Wie bei perkussiven Instrumenten nachvollziehbarerweise üblich, sind hier die Attack- und Releasezeiten sehr gering zu wählen.
VSTi bringen möglicherweise in ihrem Benutzerinterface eigene Kompressoren mit oder die benutzten Samples selbst sind bereits ausreichend komprimiert. Jedenfalls ergab sich im Rahmen des Beispielsongs keine Notwendigkeit für die Anwendung eines Kompressors bei MIDI Spuren.
4.3.2 Frequenzen
Eine weitere Möglichkeit, das Klangbild der Einzelspuren deutlich zu verändern, ist der Equalizer. Viele Audiogeräte für Endanwender besitzen jeweils Einstellmöglichkeiten für hohe, mittlere und tiefe Frequenzen. Im Bereich der professionellen Audioproduktion stehen dem Tontechniker selbstverständlich viel präzisere Manipulationsfenster zur Verfügung, um gezielt kleinere Frequenzbereiche innerhalb der vom Menschen hörbaren 20 kHz abzudämpfen oder hervorzuheben. Abbildung 33 zeigt die Equalizereinstellung einer Spur, die nicht verändert wurde und allen Frequenzen des Zielsignals die gleichen Lautstärken des Quellsignals zugesteht:
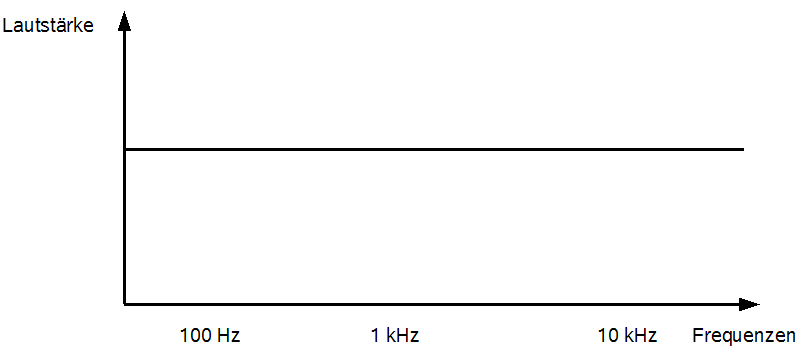
Abbildung 33: Neutraler Equalizer
Gemäß der durch den Menschen wahrnehmbaren Wichtigkeit ist die Frequenz logarithmisch dargestellt. Jedes Musikinstrument besitzt einen ungefähr festlegbaren Bereich, in dem es hauptsächlich Töne spielen kann. Laut Quelle [8] beginnt dieser Bereich bei etwa 47,2 Hertz (Ton E1) der Bassgeige, die ein Frequenzband bis 264 Hertz (Ton h) einnimmt. Die Violine beginnt bei etwa 196 Hertz und endet bei ca. 3700 Hertz, was in etwas einem f4 entspricht. Die Piccolo Flöte ist das klassische Instrument mit der höchsten Tonlage, welche bei ca. 4200 Hertz (c5) endet. Die menschliche Stimme umfasst in etwa den Bereich von 87 Hertz (F) bis 1100 Hetz (c3; Bass: 87 bis 350, Bariton: 98 bis 400, Tenor: 130 bis 500, Alt: 174 bis 700, Sopran: 250 bis 1100 Hertz). Siehe Abbildung 34.
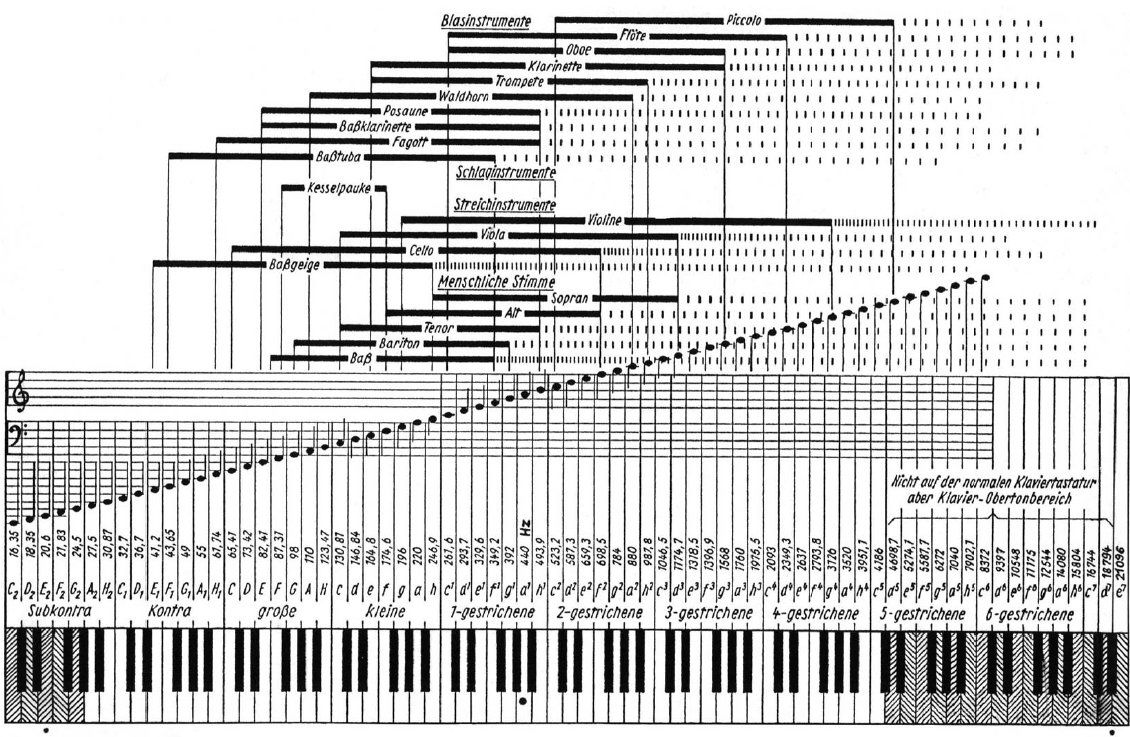
Abbildung 34: Frequenzbereiche klassischer Instrumente (aus [8])
Wichtig anzumerken ist, dass es sich bei diesen Frequenzbereichen um die Töne handelt, die ein Instrument in der Lage ist, zu spielen. Dies bedeutet bei Weitem nicht, dass das Instrument nicht Frequenzen erzeugt, die weit oberhalb der 4,2 kHz der Piccoloflöte liegen.
Um herauszufinden, welche Frequenzen am Klang einer Audioquelle beteiligt sind, ist es nötig, das Quellsignal einer Spektralanalyse zu unterziehen. Hierbei werden auf Grundlage der Eigenarten der verschiedenen Amplituden die beteiligten Frequenzen ermittelt. Die mathematische Grundlage hierfür bildet die Fourier Analyse, die allerdings nur bei kontinuierlichen Signalen funktioniert. Die Signale, die gemäß den Kapiteln 3.1 und 3.2 dieser Arbeit digitalisiert wurden, liegen in diskreten Werten vor, weswegen eine diskrete Fouriertransformation (DFT) vorgenommen werden muß. Diese ist wie folgt definiert:
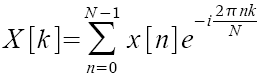
N steht hierbei für die Gesamtanzahl der Samples des digitalen Audiosignals und x[n] ist demnach ein spezielles Sample. Alle Samples werden mit einem Oszillator mit der Frequenz k gewichtet. X[k] stellt also den Anteil der Amplituden dar, die einem bestimmten Frequenzkanale k entsprechen.
In dieser Form ermittelt die DFT die Gewichtung des Frequenzkanales k über das gesamte Signal, was zur Ermittlung aller beteiligten Frequenzen auch sinnvoll ist. Ist man interessiert am Echtzeitverlauf der verschiedenen Frequenzen, muß man das Signal in kleine Fenster unterteilen und die DFT jeweils erneut anwenden. Dies kann allerdings nur mit einer gewissen Genauigkeit passieren, weil die Fensterlänge nicht die Länge einer tieffrequenten Amplitude unterschreiten darf (Unschärferelation).
In Audioproduktionsprogrammen wie Cubase oder Samplitude steht die DFT gewöhnlicherweise als Fast Fourier Transformation (FFT) zur Verfügung, die einen weitaus geringeren Rechenaufwand erfordert.
Durch eine solche Analyse und durch das Wissen, welche Frequenzen ein bestimmtes Instrument für gewöhnlich einnimmt, kann man die Frequenzen einer Audiospur gezielt manipulieren.
Wie genau die Equalizereinstellung für eine bestimmte Audiospur vorgenommen wird, unterliegt letztlich dem Geschmack des Tontechnikers, bzw. des Hörers. Wichtig ist bei dieser Art der Manipulation vor allem, Frequenzen nicht derart anzuheben, dass sie übersteuern oder unangenehm klingen, was vor allem in hohen Frequenzen schnell der Fall sein kann.
Darüberhinaus kann es sinnvoll sein, Instrumente, die nur in einem bestimmten Frequenzbereich Töne produzieren, in den an anderen Bändern abzudämpfen. Ein Beispiel hierfür können die Base Drum oder der Bass sein, die nur relativ tiefe Frequenzen erzeugen. Die Anwendung eines Tiefpassfilter könnte in diesem Falle störende Nebengeräusche, die mit aufgezeichnet wurden und möglicherweise laut genug sind, um ein eventuelles Gate zu triggern, beseitigen. Abbildung 35 zeigt einen solchen Tiefpassfilter, der, wie der Name vernuten lässt, nur tiefe Frequenzen passieren lässt.
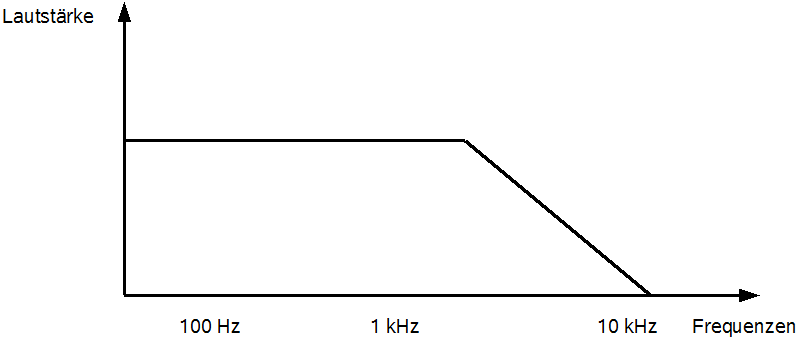
Abbildung 35: Tiefpassfilter
Die genaue Frequenz, ab der die nachfolgenden, höheren Frequenzen gedämpft werden und in welcher Intensität, kann dabei situationsabhängig sein und vom Tontechniker gewählt werden. Bevor man einen Tiefpassfilter auf ein Instrument anwendet, sollte man aber bedenken, ob das Instrument vielleicht bestimmte hohe Frequenzen für seinen Klang benötigt. Im Falle des Basses könnten dies die weiter oben angesprochenen Quietschgeräusche bei der Bewegung der Finger über die Seiten sein. Bei der Basedrum könnte dies der Anschlag des Schlegels auf das Fell der Basedrum sein. Auch hier entstehen hohe Frequenzanteile, die eventuell charakteristisch sein könnten und durch einen Tiefpassfilter entfernt würden.
Je nach Anwendungsfall kann ein Tiefpassfilter auch als Höhensperre, Höhenfilter, Treble-Cut-Filter, High-Cut-Filter oder Rauschfilter bezeichnet werden.
Natürlich gibt es auch eine hochfrequente Entsprechunng des Tiefpassfilters: den Hochpassfilter. Abbildung 36 zeigt einen solchen.
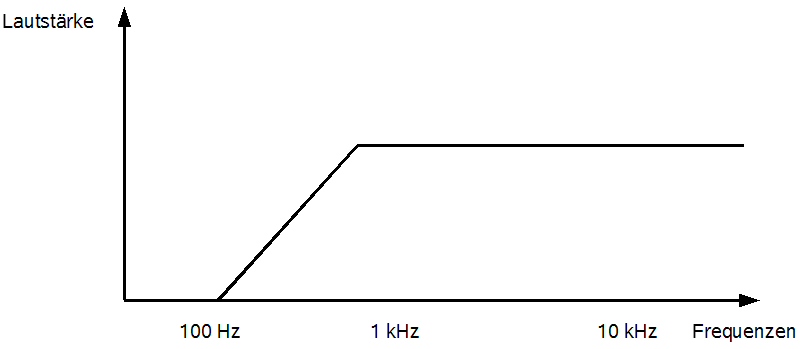
Abbildung 36: Hochpassfilter
Hochpassfilter, anwendungsbezogen auch bezeichnet als Tiefensperre, Bassfilter, Low-Cut-Filter, Bass-Cut-Filter, Trittschallfilter oder sogar Rumpelfilter, entfernen die tiefen Frequenzen aus einem Audiosignal. Bei Instrumenten wie der E-Gitarre kann ein solcher Filter sehr sinnvoll sein, da viele Gitarristen dazu neigen, einen sehr basslastigen Sound bei ihrer Verzerrung einzustellen. Allerdings „konkurrieren“ diese Frequenzen dann mit denen des Basses, wodurch ein undifferenzierter Sound entsteht. Dies geschieht nicht, wenn man der Gitarrenspur die tiefen Frequenzanteile herausfiltert. Zwar klingt die Gitarre alleingestellt dann relativ dünn, im Gesamtmix dafür umso besser.
Eine letzte Art der Bandfilter ist das Notch, auch genannt Bandsperre oder Bandstoppfilter. Im Gegensatz zum Hoch- oder Tiefpassfilter liegt das blockierte Frequenzband nicht am oberen oder unteren Ende der Frequenzskala, sondern mittendrin. Abbildung 37 zeigt einen Notchfilter.
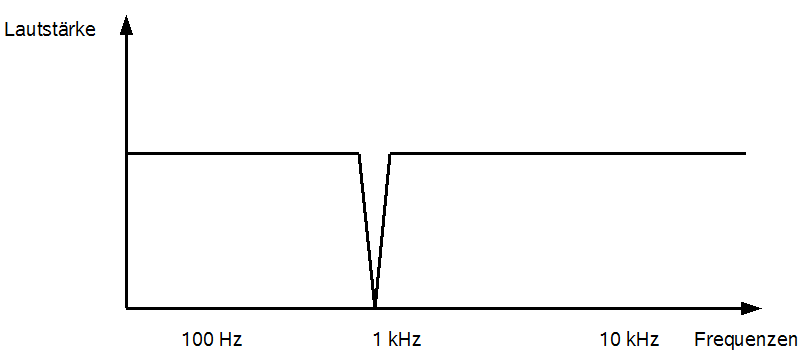
Abbildung 37: Notchfilter
Auch hier kann natürlich die Breite des gedämpften Bereichs und die Härte des Schnittes gewählt werden. Ein solcher Filter kommt in erster Linie bei Live Auftritten zum Einsatz, um bestimmte Frequenzen, die Rückkopplungen verursachen können, unterdrücken zu können. Bei Audioaufnahmen kann der Notchfilter eventuelle Störgeräusche präzise entfernen, sofern diese in einem bestimmten Frequenzband auftreten und in diesem Band keine oder vernachlässigbar wenig Nutzinformationen liegen.
Wie bereits weiter oben erwähnt, unterliegt es – von diesen speziellen Equalizereinstellungen abgesehen – letztlich dem Geschmack des Hörers, welche Filtereinstellungen gut genug für das zugrundeliegende Audiomaterial klingen. Im Beispielsong wurde vor allem die Rhythmus E-Gitarre in ihren Höhen verstärkt, da der Verstärker in natura recht dumpf klingt. Aber auch fast alle anderen Instrumente wurden geringfügig in ihren Frequenzen manipuliert.
4.3.3 Pitch Shifter und Time Stretcher
Manchmal kann es nötig sein, die Tonhöhe einer Audiodatei nachträglich zu ändern. Dies erreicht man beispielsweise dadurch, dass man sie schneller oder langsamer ablaufen lässt. Im Verhältnis zur Abspielgeschwindigkeit ändert sich dann auch die Tonhöhe. Dies ist ein bekannter Effekt der akustischen Vorspulfunktion an alten Kassettenrekordern oder der Jog Funktion anderer Bandgeräte. Der Nachteil besteht hauptsächlich darin, dass sich sowohl die Geschwindigkeit der Audiodatei ändert, als auch ihr Klang: spielt man beispielsweise die menschliche Stimme schneller ab, entsteht der „Micky Maus Effekt“, der die Stimme klingen lässt, als hätte der Sprecher kurz zuvor Helium eingeatmet. In Hostprogrammen der modernen Audioproduktion arbeiten jedoch mächtige Algorithmen, die diesen Effekten in beeindruckender Qualität entgegenwirken können.
Abbildung 38 zeigt das Manipulationsfenster der Tonhöhe einer Audiodatei in Programm Cubase SX3.
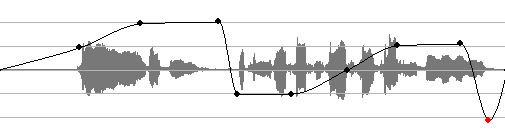
Abbildung 38: Pitch Shifter
Die eigentlichen Audiodaten sind grau dargestellt. Die horizontalen Linien stehen für Halbtonschritte und die frei durch den Tontechniker manipulierbare Linie gibt die Zieltonhöhe an. Die Audiospur in der Abbildung wird also nun zu Beginn einen Halbtonschritt höher wiedergeben, danach zwei Halbtonschritte höher und ab der Hälfte einen Halbtonschritt tiefer als das Original, und so weiter.
Wohlgemerkt handelt es sich hier um eine im Zeitverlauf frei wählbare Tonhöhenkorrektur, die die Abspielgeschwindigkeit nicht beeinflußt. Darüberhinaus kann man den sogenannten Formant Modus aktivieren, der zusätzlich bewirkt, dass die Stimmcharakteristik erhalten bleibt. Dies ist zwar rechenintensiver, funktioniert aber in beeindruckender Art und Weise: selbst bei einer ganzen Oktave Unterschied nach oben oder unten ist die Stimme eindeutig wiederzuerkennen, ohne dass ein Micky Maus Effekt o. ä. eintritt. Mit diesem Effekt ist es ohne weiteres möglich, einige verunglückte Töne des Sängers im Nachhinein präzise gerade zu rücken.
Wie weiter oben bereits angemerkt wurde, muß ein Sänger aber nicht nur die richtigen Töne treffen (wobei man ihm auch - wie gezeigt - technisch helfen kann), sondern auch ein gutes Timing besitzen. Mit den Möglichkeiten der digitalen Audioproduktion kann aber auch ein zu unpräzises Timing im Nachhinein korrigiert werden. Ein Time Stretcher ist ein Effekt, der die Abspielgeschwindigkeit ändert, ohne die Tonhöhe (und die Stimmcharakteristik) zu beeinflußen. Er arbeitet also mit dem oben beschriebenen Pitch Shifter zusammen und kann in entsprechend hochwertigen Programmen ebenso selektiv angewendet werden. Abbildung 39 zeigt die Möglichkeit zur Timingkorrektur in einem Vorher- und Nachherbild:
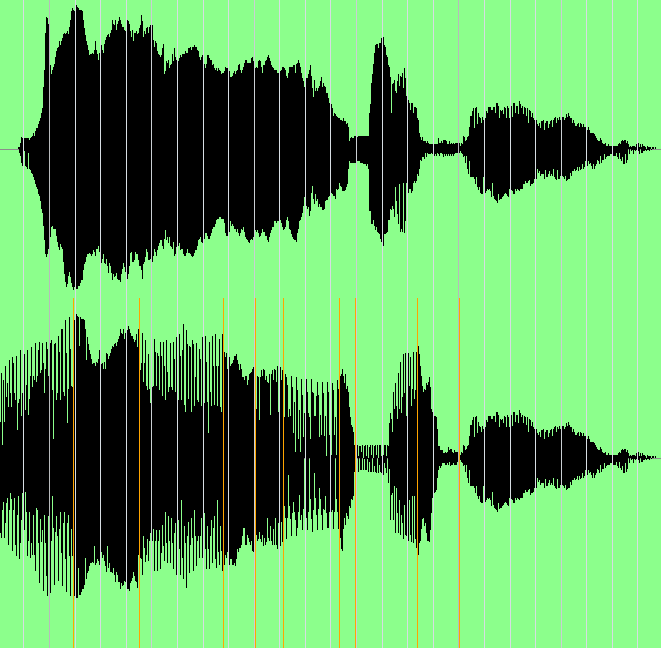
Abbildung 39: Time Stretcher
Oben sind die Original-Audiodaten zu sehen. Unten sind im zeitlichen Verlauf manipulierte Audiodaten zu sehen, die jeweils an einem Ankerpunkt (vertikale Linien) verschoben wurden. Dies geschieht per Drag and Drop. Ein praktischer Anwendungsfall wäre, wenn ein Sänger die entscheidenen Silben nicht genau auf dem zugrundeliegenden Rhythmus gesungen hat. Diese Silben können akustisch identifiziert und mit einem Anker versehen werden. Danach werden sie schlicht weiter nach vorne oder nach hinten geschoben. Es ist so tatsächlich möglich, ein eher unpräzises Timing exakt auf den Beat zu setzen.
Da es in einem solchen Falle aber passieren kann, dass eine Passage der Audiodaten durch ihre starke Dehnung zu grob aufgelöst ist, ist es grundsätzlich sinnvoll, Audioaufnahmen mit mehr als der Zielsamplerate von 44,1 kHz aufzuzeichnen.
Sinn machen diese Effekte vor allem bei einem zeit- und ortsversetzten Aufnahmeablauf, in dem der Tontechniker nicht ohne weiteres eine zusätzliche Aufnahme vom Sänger verlangen kann. Kleine Fehler können so zuverlässig korrigiert werden.
Tatsächlich kam der Effekt des Time Stretchings mehrfach im Beispielsong zur Anwendung, da das Timing eines Sängers zwar gut, aber nicht perfekt war. Diese Möglichkeit der nachträglichen Korrektur eines bestehenden Audiofiles ist eine wichtige Eigenschaft der digitalen Audioproduktion, die man in der klassischen Audioproduktion wohl vergebens sucht. Die Qualität des Beispielsongs wäre letztlich sehr viel geringer gewesen, wenn das Timing des Sängers nicht präzise gewesen wäre. Ein Pitch Shifter kam nicht zur Anwendung.
Selbstverständlich können Time Stretcher und Pitch Shifter auch bei anderen Instrumenten angewandt werden.
4.3.4 Hall, Roomsimulator und Pre-Delay
Halleffekte verleihen den im Studio aufgenommenen Klängen im Nachhinein die Natürlichkeit, die eine trockene Aufnahme nicht besitzt. Hall oder auch Nachhall (Englisch: Reverb) ist die kontinuierliche Reflektion von Schall in geschlossenen Räumen. Die einfachsten Effekte dieser Art besitzen lediglich einen einzigen Regler, der die zeitliche Länge des Nachhalls regelt (die sogenannte Hallfahne). Die meisten Reverbeffekte besitzen jedoch zusätzlich einen Regler, mit dem man den lautstärkemäßigen Anteil des „trockenen“ und „nassen“ Signals einstellen kann.
Eine weiterentwickelte Form des Halleffektes ist der sogenannten Raumsimulator (Room Simulator), der die Reflektionscharakteristika ganz spezieller Räumlichkeiten akustisch nachzubilden versucht. Dies können Kirchen, kleine oder große Hallen, Konferenzräume oder sogar Garagen sein. Zitat [9]: „Die grundlegende Idee besteht darin, dass man die Akustik eines schon bestehenden Raumes als Vorlage nimmt, um vorhandenes „trockenes“ Audiomaterial zu verhallen, so als ob es in eben diesem Raum aufgenommen worden wäre.“
Ein Raumsimulator imitiert, wie auch höherwertige Halleffekte, zusätzlich den sogenannten Pre-Delay. Die Pre-Delay Zeit ist die Zeit, die vergeht, bis ein Klangereignis von den Wänden eines Raumes zum ersten Mal reflektiert wurde. Pre-Delay ist gleichbedeutend mit dem Begriff der frühen Reflektionen, die zwischen einem Klang und dessen Hallfahne auftreten. Durch die Manipulation der Pre-Delay Zeit in einer Aufnahmeumgebung ist es möglich, Schallquellen nachträglich räumlich zu positionieren. Je höher die Pre-Delay Zeit gewählt ist, desto weiter erscheint das Objekt, das das Klangereignis erzeugt hat, für den Zuhörer entfernt. Siehe auch Abbildung 40. Im Beispielsong wurde in erster Linie der Gesang mit Hall versehen, zusätzlich die Textzeile „Ki you ancient Tiamat...“ mit einer höheren Pre-Delay Zeit. Die akustisch aufgezeichneten E-Gitarren enthielten bereits Hall aus ihrem Effektgerät und das Schlagzeug aus seinem Klangerzeuger. Es wurde grundsätzlich darauf geachtet, ähnlichen Hall für alle beteiligten Instrumente zu vergeben, da diese sonst keine akustische Einheit bilden können.
4.3.5 Stereoeffekte
Nachdem die Akustikquellen nachträglich in ihrer virtuellen Entfernung zum Hörer durch das Pre-Delay positioniert wurden, sollten sie auch im Stereopanorama verteilt werden. Mit dem Pan bezeichnet man in der Tontechnik den Panorama-Regler. Also den Regler, dessen Einstellung darüber entscheidet, wieviel des Signals im linken, bzw. rechten Lautsprecher zu hören ist. Seine Normalposition ist demnach mittig zentriert. Abbildung 40 zeigt das Zusammenspiel von Pan und Pre-Delay:
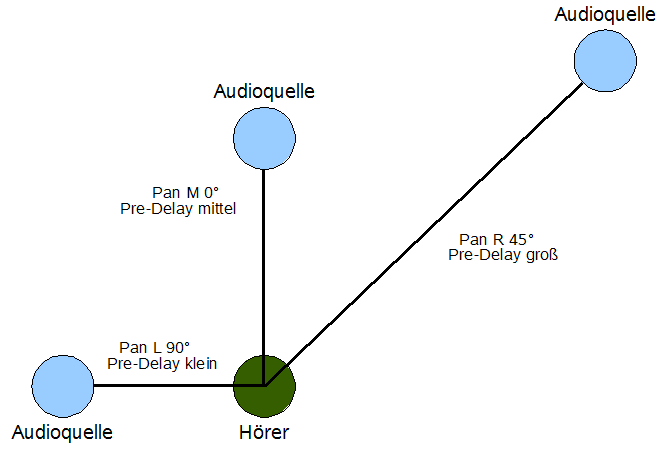
Abbildung 40: Pan und Pre-Delay
Vor der Anwendung des Pan liegen alle Audioquellen direkt frontal vor dem Hörer. Vor der Anwendung des Pre-Delay liegen sie dem Hörer sehr nah.
Alle mit einem Mikrofon aufgezeichneten Audiospuren sind naturgemäß Monokanäle. Durch ihre Positionierung links oder rechts vom Zentrum erreicht man einen differenzierten und breiteren Klang.
Im Beispielsong sind alle Instrumente leicht um die Panoramamitte verteilt. Insbesondere der Eingangsdialog der beiden Cheruben ist leicht links, bzw. leicht rechts gelegt. Enki singt zentriert. Die unterschiedlichen Solo E-Gitarren sowie die Rhythmus E-Gitarren sind komplett jeweils 90° links und 90° rechts angeordnet.
Dieser Effekt kann allerdings auch künstlich mit einem sogenannten Stereo Enhancer hergestellt werden, ohne dass der Musiker zweimal dieselbe Spur aufzeichen muß. Ein Stereo Enhancer (auch Stereo Widener genannt) wendet in der Regel folgende Effekte auf eine Audiospur an:
• Er legt zwei Kopien des Audiomaterials an
• Die beiden Kopien werden zeitlich leicht gegeneiner verschoben
• Eine Kopie wird 90° links, die andere 90° rechts ins Panorama gelegt.
Gewöhnlicherweise kann man die Verzögerung der Kopien und die Lautstärke des Originals im Kontrast zu den Kopien mit entsprechenden Reglern variieren. Der Effekt ist in Worten schwer zu beschreiben. Es entsteht ein voluminöserer Klang, der ein viel breiteres Spektrum einzunehmen scheint.
Die Entscheidung, im Beispielsong auf diesen Effekt bei den von Hand gespielten Gitarren zu verzichten und stattdessen zwei Spuren von Hand im Panorama zu verteilen, basiert letztlich auf einer Geschmacksfrage.
4.3.6 Weitere Effekte
An dieser Stelle sei noch kurz auf weitere Effekte eingegangen, die im Rahmen des Beispielsongs zur Anwendung kamen.
Allen voran erwähnenswert ist der De-Esser, der die stimmlosen Zischlaute (s, ss, ß, sch, z, tz) der Sänger dämpfen soll. Diese Zischlaute werden vor allem durch eine starke Kompression hervorgehoben und müssen gedämpft werden. Ein De-Esser senkt die charakteristischen Frequenzen im Pegel ab. Er hat meistens Presets für weibliche und männliche Zischlaute, die sich eindeutig zu unterscheiden scheinen.
Ein Exciter ist ein Effekt, der im Beispielsong nicht zur Anwendung kam und hauptsächlich bei analogen Aufnahmen Anwendung fand, wenn nach oftmaligen Abspielen die Höhen verloren gingen. Besonders dumpfen Aufnahmen verhilft er zu mehr (empfundener) Klarheit, in dem er sehr hohe Frequenzen verzerrt und lauter macht. Tatsächlich kann es schnell passieren, dass der Klang der so bearbeiteten Aufnahme bei der Anwendung viel besser klingt, aber ein unangenehmes Gefühl in den Ohren hinterlässt. Wenn er dosiert angewendet wird, kann er dem Audiomaterial aber eine gewisse Brillanz verleihen.
Sogenannte Multibanddynamiken sind Kompressoren, die nur spezielle Frequenzbänder betreffen. Meistens sind dies grob die Bereiche Tiefen, Mitten und Höhen, es gibt aber auch Effekte, die viel mehr Frequenzbänder zulassen. Im Gegensatz zum normalen Equalizer werden also hier Frequenzbänder komprimiert, statt nur im Pegel abgesenkt. Das Ergebnis ist, wie bei Kompressoren üblich, dass vormals zu leise Signale in den entsprechenden Bändern lauter werden, was zu einem sehr differenzierten Sound führen kann. Im Beispielsong wurden Multibanddynamiken erst im Mastering angewendet.
voriges Kapitel | nächstes Kapitel